This article is written by Andrew Walsh, creator of
openapi-devtoolsand nowDemystify. You can check out more of his work here. All opinions expressed are his own.
A common problem developers face is uncertainty about API behaviour. When documentation for an API is missing, outdated, or of poor quality productivity suffers a severe yet hidden penalty. This leads to wasted time, repeated effort, more bugs, and frustration that can impact morale. API documentation is critical for teams that want to be effective.
But creating and maintaining manual API documentation through standards such as OpenAPI is non-trivial. It can prove extremely challenging and time consuming to document an existing undocumented API. This often proves untenable in business environments amidst tight deadlines and competing priorities.
Solutions to this problem generate API documentation automatically. Libraries such as drf-spectacular use code structure and semantics in back-end frameworks to infer API contracts. API frameworks such as FastAPI and Huma generate OpenAPI specifications as a built-in feature. Tools like mitmproxy2swagger generate documentation from HAR files. Finally, companies such as Akita Software/Postman use network traffic metadata.
Demystify uses the network traffic metadata approach, but with a unique twist. It does not send network traffic metadata elsewhere, and uses a local algorithm optimised for space and time complexity. Network traffic data is processed on services controlled by users, saving orders of magnitude of API requests.
How It Works
An in-depth discussion on the technical architecture of this approach can be found in the following whitepaper. Here we’ll provide a high-level breakdown of how it works conceptually.
The tool generates an internal representation of an API’s contract based on HTTP network traffic that it has seen. Every time a request is made, the tool updates its internal state. It can generate an OpenAPI 3.1 specification from this state. It can also accommodate different versions of OpenAPI, or another format entirely.
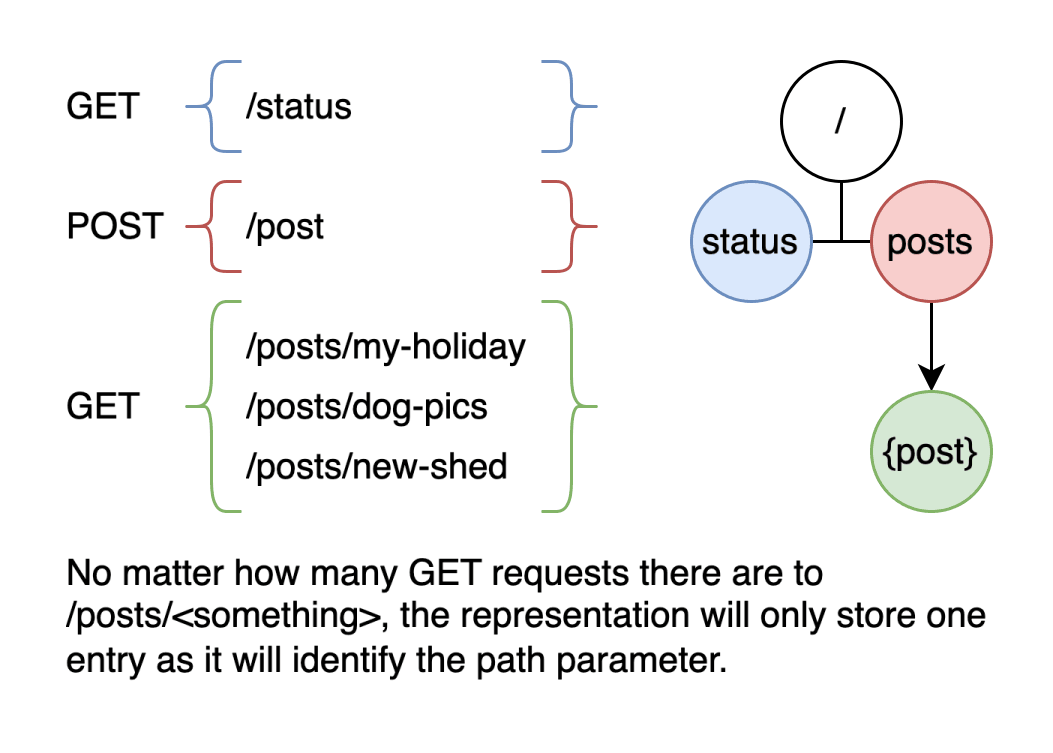
A critical feature is automated identification of
path parameters.
This means that the OpenAPI specification will feature paths like
/posts/{post} once it has seen sufficient samples such as /posts/my-holiday
and /posts/cat-pics. The algorithm behind this uses a heuristic that can be
updated easily, or swapped out entirely by users. Automated parameterisation of
path parameters is a critical feature that constrains memory usage of the
internal representation to a bounded and manageable size.
This lets us use the tool on the server side to generate an internal representation of an API without worrying about memory or performance. Users could integrate the tool using various means, such as a Docker proxy between a client and server that communicates with a self-hosted system designed to store this data and make API documentation available. Using this approach and other techniques, we can produce versioned OpenAPI specifications for any API by observing network traffic over a given period.
The technical term for this process of mapping an API’s surface and its contract is API Discovery. A unique feature of the tool is that data processing happens locally. It does not send network traffic data to third party services that perform processing on large amounts of collected data. In practice this is a massive reduction in API requests that we would otherwise need to make. This can save many thousands of dollars alone compared to other solutions. It also eliminates data protection, regulatory, and privacy concerns with sending network traffic metadata to external partners.
To summarise, the tool performs API discovery locally by accepting network traffic in the form of HAR entries. These requests contain an implicit API contract that the tool encodes. The tool uses this encoding to generate an OpenAPI specification.
Client-based and Server-based Tooling
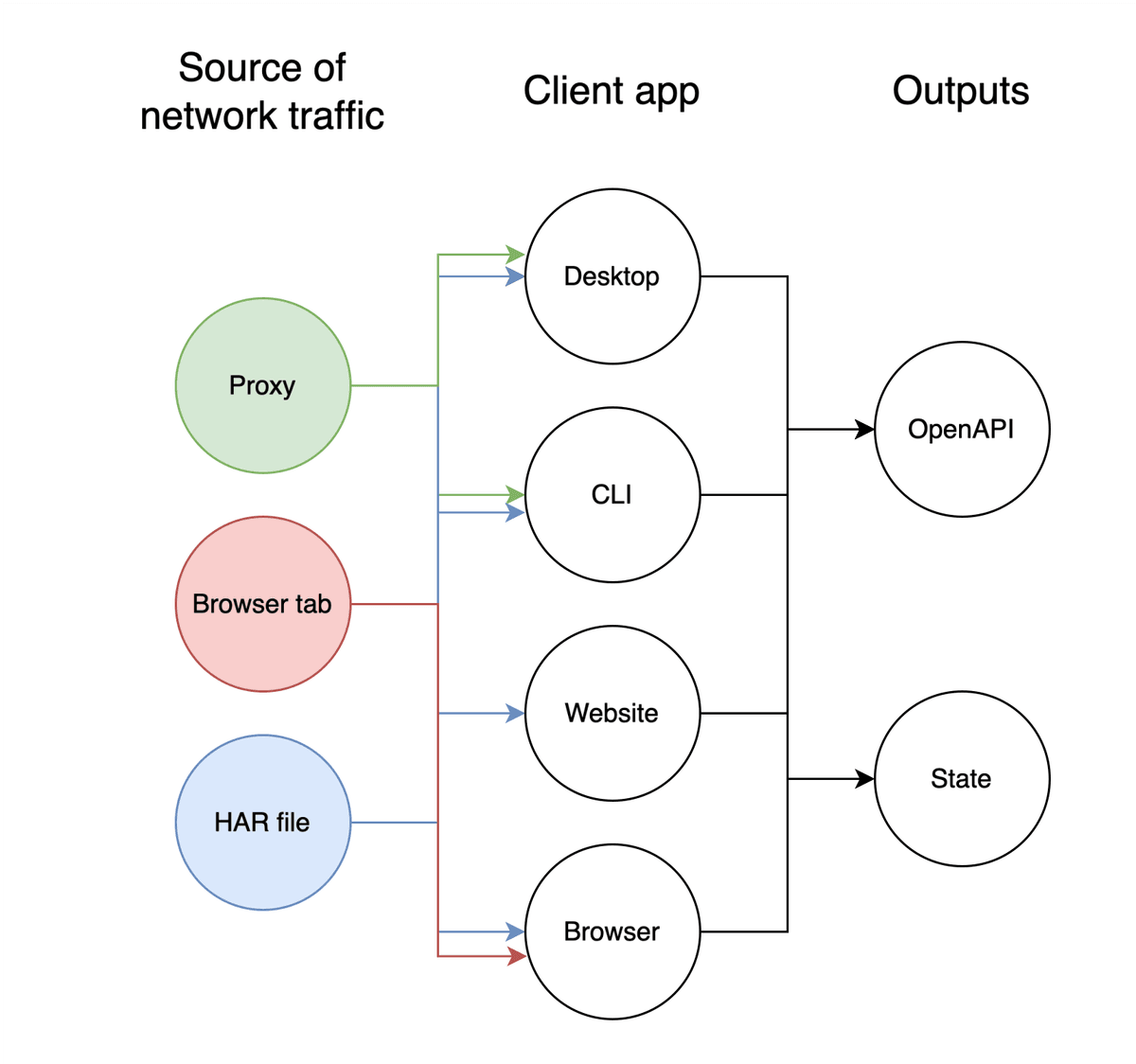
The release is split into two phases. The first has happened and is the release of standalone client-based tools and the algorithm that powers the entire system. These tools let users generate OpenAPI specifications for any API, internal or external. There is a desktop application with a proxy that can easily be toggled to capture network traffic on a local port that then becomes an OpenAPI specification in real time. There is also a browser extension in the spirit of OpenAPI DevTools, and a website that lets users upload HAR files directly. There is also a command line tool.
These applications are able to process network traffic from different sources. They let users generate API documentation for internal or external APIs, and demonstrate the algorithm’s function.
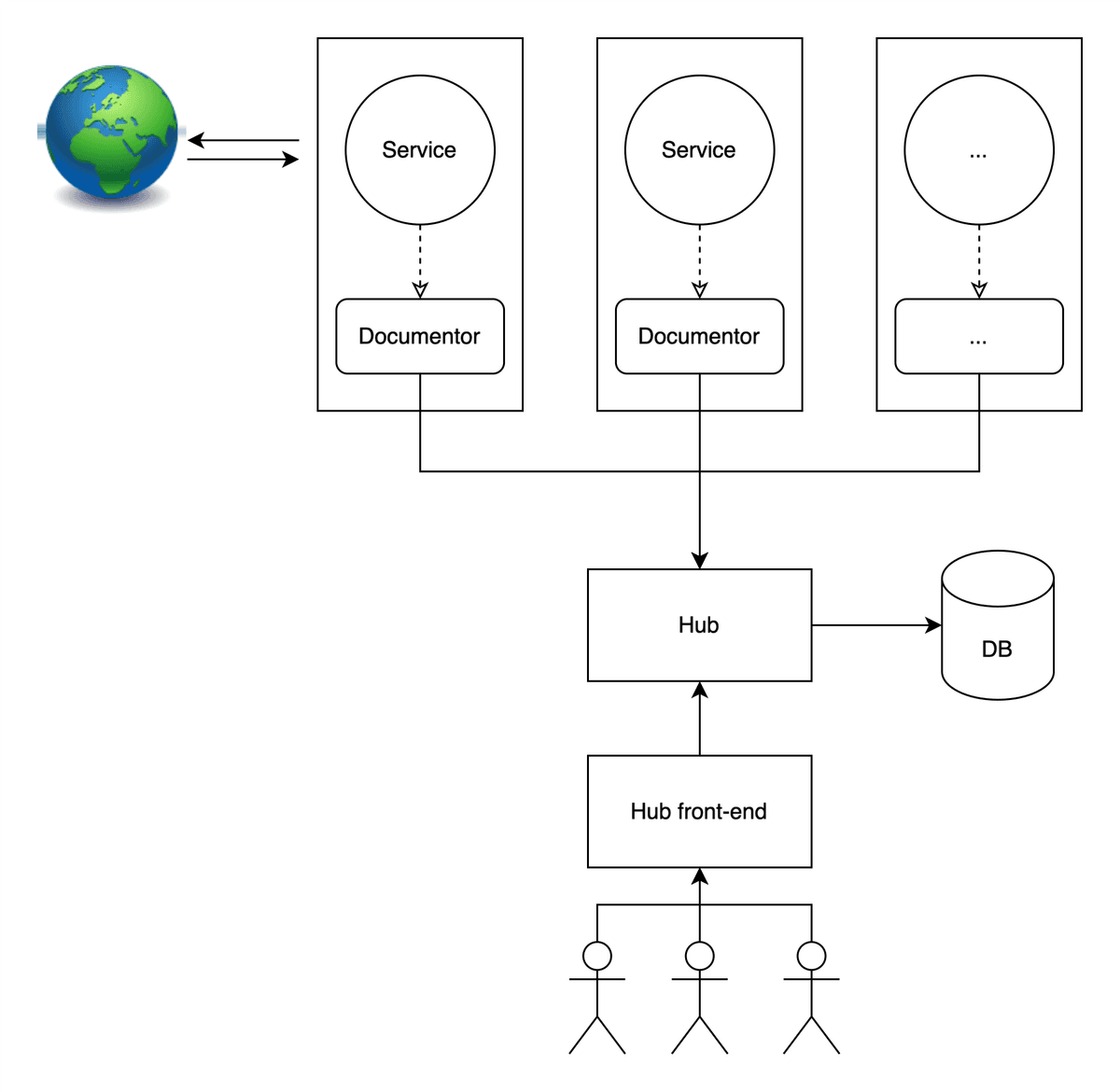
The second phase is the release of self-hosted server-based tools that can generate OpenAPI specifications for any API. This involves two components. The first being an agent that runs alongside an API through some mechanism with deployment tools such as Docker or Kubernetes. This agent would encode and maintain a representation of the underlying API, and synchronise with a second component called a hub. The hub would accept and store representations of APIs from agents, and would let users see OpenAPI specifications for all their APIs in a dashboard that updates in real time as agents push updates.
Opportunities to deliver value from there on are numerous. Users could use newly generated OpenAPI specifications with its vast ecosystem to perform tasks such as code generation, mocking, and penetration testing. They might also use LLMs to automatically describe endpoints, or perform tasks like test generation. Other possibilities include contract testing using services like PACT.
A hosted version of such a service could serve users that do not wish to self host. There are opportunities to create new solutions that improve observability of API surfaces and contracts for organisations. All while respecting data protection concerns and regulations such as GDPR.
Use It Today
Check out the desktop app and generate an OpenAPI specification for a server by setting up the proxy. Specify a local port to listen to, and a host server to forward to. The host server may be local or remote. Then send requests to the local port and watch your API requests become an API contract.