Oh no, there’s another spec to keep up with. My first reaction to Agentic Resource Discovery (ARD), the standard Google announced on June 17, was to brace for yet another thing to implement and then keep updated. Fortunately ARD is light, and it feels like one of the more inevitable steps in agentic discovery: agents already call your APIs and MCP servers, and ARD gives them a standard way to learn those servers exist in the first place.
If you’re familiar with the .well-known pattern and its usage, you’re 50% of
the way there already. Let’s dive in.
- Teams that already host an MCP server or API and want agents to discover it
- Platform owners deciding where a machine-readable capability catalog should live
- Anyone who runs a Zuplo gateway and wants a .well-known endpoint without standing up new infrastructure
What ARD is
ARD is an open standard, licensed under Apache 2.0, for publishing, discovering, and verifying AI capabilities across the web. The announcement frames it as three questions an agent has to answer before it can use anything: “Where does the right capability live? Which capability should I actually use? And how do I verify it’s safe to connect to?”
There is no standard answer today. An agent can speak MCP fluently and still have no idea your MCP server exists unless someone hands it a URL. ARD fills that gap with two pieces:
| Piece | What it is | Who runs it |
|---|---|---|
| Catalog | A file describing your capabilities, published under your own domain. Domain ownership is the cryptographic root of trust. | You |
| Registry | A search engine that crawls published catalogs, indexes them, and attaches verifiable trust metadata so an agent can decide what is safe to connect to. | A third party |
The catalog is the part you own and publish. In the words of the spec, it describes capabilities that “can include things like MCP servers, A2A agents, OpenAPI tools, or even other nested catalogs” (A2A is the agent-to-agent protocol). If you have read about WebMCP and how websites expose tools to agents, this is the discovery layer that sits a step earlier: WebMCP is how an agent calls your tools, ARD is how it finds out you have any.
Inside the manifest
The catalog is a static JSON file named ai-catalog.json. Here’s one for
Changeloggle, a demo application whose MCP server I run on Zuplo using the
awesome
dynamic MCP server functionality.
The shape follows the
spec’s publishing guide:
Reading it top to bottom:
| Field | What it holds |
|---|---|
specVersion |
Manifest format version, currently "1.0". |
host.displayName |
Human-readable name for the publisher. |
host.identifier |
A did:web value tied to your domain. Only the domain owner can serve content from it over HTTPS, so controlling the domain proves the catalog is yours. That is ARD’s root of trust. |
entries[].identifier |
ARD’s urn:air:<your-domain>:<namespace>:<agent-name> pattern. Here the host is the domain, server the namespace, changeloggle the name. |
entries[].displayName |
Human-readable name for the capability. |
entries[].type |
The resource media type, here application/mcp-server+json. |
entries[].url |
Where the resource lives. For Changeloggle’s MCP server, that’s its /mcp endpoint, the address a client connects to. |
entries[].capabilities |
Array of capability names the resource exposes. |
entries[].description |
Plain-language summary of what the resource does. |
entries[].representativeQueries |
The quiet heavy lifting: two to five natural language examples that let a registry match your server to a user’s intent by semantic search, not by someone already knowing its name. |
Swap the host (changeloggle-main-fbddb8e.d2.zuplo.dev) for your own domain in
the did:web value and in each urn:air identifier. For testing you can use
the working-copy domain Zuplo hands you (the one ending in zuplo.dev), as I’ve
done here. For production, add a
custom domain for your API and
update both identifiers to that, since the domain is ARD’s root of trust and
your catalog should be served from the domain you actually own.
The spec is strict about how you serve the file:
- Over HTTPS.
- With
Content-Type: application/json. - With
Access-Control-Allow-Origin: *, so any agent can read it cross-origin.
Build the manifest
You could drop a static file on a bucket and call it done. Serve it from your gateway instead because the gateway is already the front door for the MCP servers and APIs the catalog points at. The thing doing discovery and the thing being discovered live in one place, so the catalog can’t drift from what you expose.
Keep the catalog in a module and return it from a function handler. Zuplo
projects hold this code in the modules/ folder, alongside config/ where
routes.oas.json lives:
Create modules/well-known.ts by clicking the three-dot menu next to modules
and choosing New Empty Module:
Name it well-known.ts and paste in the handler:
That is the whole content side. The handler returns the manifest as JSON, and the route handles CORS in the next step.
Custom function handlers in Zuplo
The full handler API, including how to read params and query strings and return a Response with custom headers.
Add the route
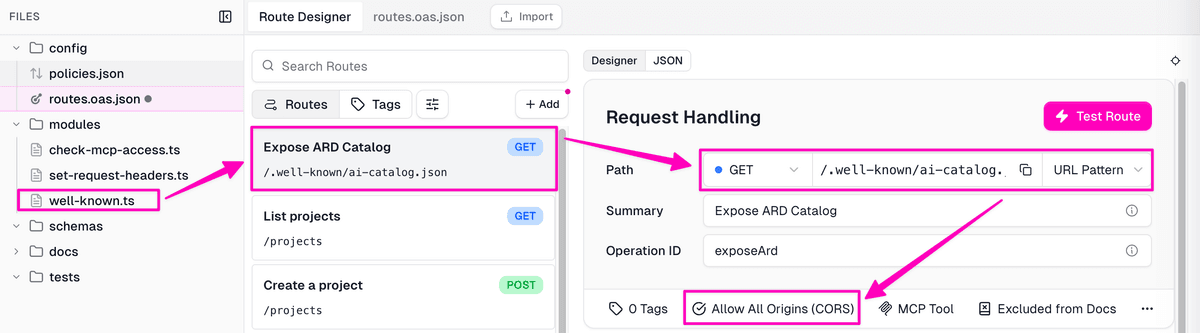
Now wire the handler to the path ARD expects, from the Route Designer without touching the config files by hand:
- Open your project in the Zuplo portal and go to the Route Designer
(
routes.oas.json). - Click + Add and choose REST Operation, then give the route a summary
like
Expose ARD Catalog. - Set the method to GET and the Path to
/.well-known/ai-catalog.json. - Under Request Handling, set the handler to Function, then point it at
the
./modules/well-knownmodule and thehandleWellKnownexport. - Turn on Allow All Origins (CORS) so any agent or registry can read the catalog cross-origin. That is why the handler above doesn’t set the header itself.
- Leave the inbound policies empty. A Zuplo route is public unless you attach an authentication policy, and this endpoint needs to stay public so registries and agents can fetch it.
Common mistake:
Leaving the inbound policies empty is intentional here, not an oversight. The catalog has to be world-readable, so resist the reflex to bolt auth onto it. Save auth for the MCP servers and APIs the catalog points at, not the catalog itself.
Saving the route writes this into routes.oas.json, which is what you would
edit directly if you prefer the IDE:
Deploy, then fetch https://your-gateway/.well-known/ai-catalog.json. You
should get the catalog back as application/json, ready for any agent to read.
Point at your MCP server
We already front MCP servers for teams whose agents reach those tools by hardcoded URL today, and ARD is the piece that turns that into crawlable discovery. The catalog is only as useful as what it points at.
If you are running the
Zuplo MCP server, the url
field points at the MCP endpoint your gateway already hosts, and the
capabilities array is the set of tools you have chosen to surface. The gateway
fronts the server, decides which tools are visible, and now advertises it
through ARD, all from the same project.
That is what makes this more than a metadata exercise. An agent reads your
catalog, sees the Changeloggle MCP server with a createChangelog capability
and a representative query that matches what its user asked for, and connects,
while your gateway still enforces auth, rate limits, and tool curation on every
call.
ARD is young and the registry side is still filling in. Registries crawl and
index published catalogs rather than asking you to push to them, and the spec is
explicit that hosting alone doesn’t guarantee inclusion. It also defines
optional DNS records for the case where you can’t host at the standard
.well-known path and need to point discovery at an alternate location.
Either way your job ends at serving the file, which costs almost nothing if your gateway is already in place: one module, one route, and the agents crawling the web can find what you have built.